Every now and then I see in technical forums questions such as this: How do I find the most occurring word in my Word document? Or PDF document? Or Emails? etc. The question is a valid one if that’s something you’re curious about or need to find out in your professional role. In this blog, I explain how I would go about it.
There are many ways you can do this yourself. That is, without having to buy a converter or set of other applications. However, in all cases, I believe you’ll need to leverage some of your programming prowess. Word or PDF isn’t easily going to find that information for you. Depending on your preferences, you could use VBA code (I wouldn’t, but that’s because I know more powerful languages with slicker syntax) for Word. You could also use python-docx library to manipulate Microsoft Word documents. As for me, I try to minimize dependencies as much as I can on external libraries and even if it means a little extra code, I dig into my current toolbox and figure it out. This way: 1) I don’t have to remember which library, and be enslaved to its syntax and bugs 2) I will actually remember the solution longer and the solution will be more robust in the long run regardless of what library is supported or not. Nevertheless, there are some crucial libraries we have to depend on that are not going away, and that’s just fine with me.
Objective
Find the most occurring word in a document (whatever the source format may be). As a bonus, I’d like to know how many is “most”, and how about top 3, top 5, top 10? I’d like to know those too.
Setup
First thing I’d like to do is normalize the format (I’m using this term loosely here, not in DBMS terms on purpose)…I’d like to bring the source data into a form that I can work with for this objective. Then I’ll apply some clean-up on the data to get the raw words, then I’ll do some more cleanup and finally get the results. Here are my steps:
- Convert the source document into text. We’re looking for words stats, not images, so binary is not required at all here. Every decent content development application will export its core contents to text, even metadata, but we’ll ignore the metadata and focus on core content.
- Clean up the content by removing some “noise” from the text (I’ll show those later).
- Load up the content and split the content into words, and save each word into a list.
- Calculate the frequencies in that list. Show the results, and save the list of curated words into a new file for further analyses including importing into other apps like Excel.
Example & Solution
I’m going to use a sample news article (from a website, plus I added some extra info for testing) and saved it as a Text file (you can use Word to save as Text, or numerous other applications as you wish). Once the file is saved, I’ll put my Python code to work.
The text may look like this: 
My code opens the entire file content into memory and replaces punctuations like:
, " / ; : \
etc.
e.g.
content.replace(',', '')
would replace commas with nothing. Assuming content is the returned value from open() used to open the file. Note that I didn’t replace them with a space/blank…because in a normal content there will always be a space after a punctuation! It just saves Python from doing unnecessary calculations, but we could if we have to.
To remove double-quotes, first I get its character code, which is ASCII 34. So, by calling
content.replace(chr(34), '')
I can remove that as well…this is done this way because “” is part of the syntax used in most languages and requires special handling. Another thing that can cause problems for analysis later on are mathematical symbols in strings such as operators +, =, – as they also have special meanings in code, even when importing into Excel. To be safe, I also clear those out, except I don’t want to lose track of hyphenated words, if any, such as “self-esteem”, “word-of-mouth”, etc. So I replace the problematic “-” operator with an underscore (otherwise, Excel or DB apps would be really unhappy):
content.replace("-", '_')
Next, no one really cares about preposition words (which are useful for the language but not so much for analysis of this type) such as: on, in, the, at, etc.
So I replace them also but this time with a space because the surest way to replace a string “on” with something else is to ensure that it’s actually a word by itself and that’s the only one we want to address. If we didn’t think of that, the word “only” would become “ly” by removing “on”. If you doubt it, try it with some example strings and you’ll be aware of the issue.
Now that I have a long string cleared of the “noise” words, I can start slicing it into pieces of words (which means separated by at least one space; my code handles extra spaces) and store each word as an individual element in an array in memory.
for word in content.split(): if (len(word) >2): wordlist.append(word)
The reason is I’m trying to further fine-tune the words selection by removing any of the prepositions or other acronyms I may have missed and ensure that only words with 3+ letters are considered. Of course, this is all customizable according to situation.
Now we see in memory, the words are as:
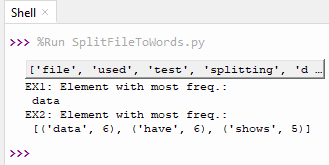
Now we can quickly find the most-occurring word by:
max(set(wordlist), key = wordlist.count)
where wordlist is a List object.
And the output we see for this file is: “data”
It’s okay but not really that helpful because we don’t know how many times it occurred, and we don’t know if another word also occurred the same amount of times! I’d like to know that one too. However, this method won’t show us that level of information.
For that, I resort to collections module of Python, which gives us Counter feature. So now, I can do cool stuff like:
from collections import Counter c = Counter(wordlist) res=c.most_common(3)
and res would hold this: [(‘data’, 6), (‘have’, 6), (‘shows’, 5)]
This shows me the word ‘data’ and ‘have’ are tied for the most occurring word, each appearing 6 times in the document, followed by the word ‘shows’, 5 times. This is very powerful, because I can do top 5, top 10, even in percentages such as give me top 2%.
Now let’s take this one step further 🙂 I want to save this curated list of words into a file, a text file, that I can import into Excel or any other app or editor at a later time, for other purposes (e.g. build a Word Cloud. See my older post on how to build a word cloud in Excel and PowerBI ).
We need to however convert the List object to a string before writing. This can be done with: delimiter.join(wordlist)
We don’t need pandas here since it’s a simple text file with one column. We want each word to appear on its own line. So, the delimiter var ab ove is ‘\n’ which make the statement:
'\n'.join(wordlist)
This will save the final output:
f = open(<filename.ext>, "w") f.write(words_str) f.close()
Could we do this in Excel completely? Not really…we can find the first match of words. For numeric values, we could use MODE.MULT() to find a range of matches but that won’t work in this case.
The one that seems to work is to get the indexes of matches using MATCH() and then find their frequency using MODE() and then passing this to INDEX() to extract the actual value.
The complete formula pattern is
=INDEX(range,MODE(MATCH(range, range,0)))
and it will return ‘data’ as the most occurring word, which is correct but doesn’t tell us that it was tied with ‘have’ as well. Where range is the range of cells containing the words in your column in Excel.
In Excel, then we could find how many by COUNTIF() on the range by using that returned word ‘data’.
That’s an example of power when using multiple languages and tools together to solve an end-to-end problem. This is just a little taste of the real world situations 🙂
This post is not meant to be a step-by-step, detailed tutorial, instead to serve key concepts, and approaches to problem-solving. Basic->Intermediate technical/coding knowledge is assumed.
If you like more info or source file to learn/use, or need more basic assistance, you may contact me at tanman1129 at hotmail dot com. To support this voluntary effort, you can donate via Paypal from the button in my Home page, or become a Patron via my Patreon site. A supporter/patron gets direct answers on any of my blogs including code/data/source files whenever possible.