This is a continuation of the Dictionary Challenge previously completed. To follow along, you should read that post here.
So, we have already downloaded a free Webster dictionary but completely unformatted and unstructured. So, we created a new file in a more structured way that our program can process. The code is in the previous post. Let’s see how this new “curated” file looks now…below is a snippet:
ARDVARK
AARDWOLF
AARONIC
AARONICAL
ABACA
–snip–
ZYME
ZYMIC
ZYMOGEN
ZYMOGENE
ZYMOGENIC
ZYMOLOGIC
ZYMOLOGICAL
ZYMOLOGIST
ZYMOLOGY
ZYMOLYSIS
ZYMOME
ZYMOMETER
ZYMOSIMETER
ZYMOPHYTE
ZYMOSE
ZYMOSIS
ZYMOTIC
ZYTHEM
ZYTHEPSARY
ZYTHUM
–end–
There happens to be over 110,000 words! And a few extra things I had to do to create this curated file:
- Remove words that are less than 3 letters (only because I wouldn’t use those for my imagined word game).
- Remove entries that have numbers in them.
- Remove entries with famous names (pronouns).
- Remove duplicate entries. e.g. “Plane” has multiple meanings, and in Webster, each one appears on its own obviously. For my purposes, I only need a single instance of a legal, English word regardless of its different meanings.
- Remove everything but the words! i.e. No meanings/description texts in our curated file.
- There were several instances, where words appeared in a single line separated by semicolons (;)…this was causing incorrect results when calculating the length of words, since the code the way I wrote it would interpret it as a single line and assumes only ONE word per line.
To fulfill the above requirements, I needed to do some manual post-clean-up but it wasn’t so bad since most of it was already cleaned by the code.
Now, this file is looking great! We can actually start to read this dictionary and start producing some metrics! Let’s do it…
The Code:
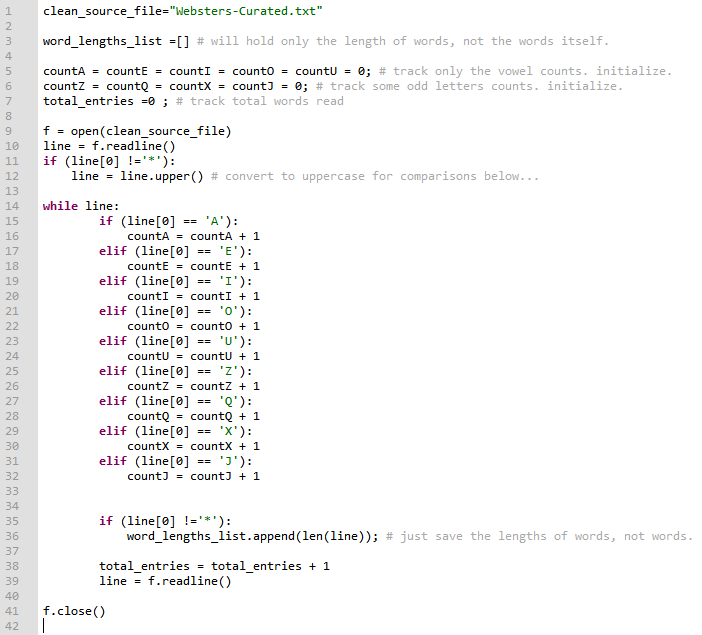
Explanation:
To make it easier of my PC (don’t have a fast machine, or tons of RAM!), I read the dictionary file line-by-line and instead of storing all the words, I calculate the length of each word (in this case, a line == a word since that’s how I created this structured dictionary file in part 1), then only store the length in a list word_lengths_list[]. That way, I can generate almost all the metrics I want. Also, I declare some simple integer variables (there are fancier ways to do this, but I opted for simplicity here) and if the first character of each line (i.e. word) starts with that character I’m interested in, I increment the counter. So, in this case…all words starting with vowels, words starting with Z, Q, X, and J (because I find those to be “odd” and interesting). In the while loop, I also keep count of total words read in total_entries variable.
NOTE: In Python, indentation is EXTREMELY important. Pay attention to the if, while, open, close statements’ locations above. Having the image snapshot above of the code allows me to show exact indentation. Any change to that will change the logic and flow and the program will not generate the expected output.
In lines 11 and 35, you’ll notice I check for “*” character and don’t do anything if the line starts with it. That’s because after my first program created the curated file, I manually added some comments for myself starting with “*”. So, we don’t want to use those lines for our measurements.
Show Metrics:
Now it’s time to show all the loaded variables by the simple print() statement. We convert the integer values to strings str() function for printing in the same statement.

More Metrics:
We have enough information in memory at this point to also find the MAXIMUM length of a word that appears in my curated Webster dictionary, the AVERAGE length of ALL words, and the TOTAL number of entries…
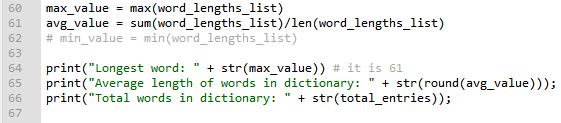
The Final Output:
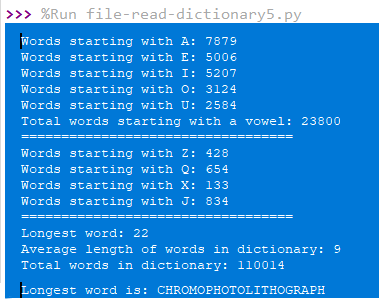
And tada! Here’s our much sought-after answers!
Exercise:
We know the longest word is 22 letters. But we don’t know what the word is! Why? Because we never saved the words themselves in memory to account for speed and efficiency. So, how would we get that without having to store the words themselves?
HINT: One way is to write another piece of code that relies on this program’s knowledge that longest word is x characters, and search the dictionary for that specific length and store ONLY that word instead of hogging the memory with 110,000+ words.
That’s what I did later to the program to generate the longest word in the output (see above).
Remember, our challenge was to:
- Get an English dictionary.
- Then find how many words start with vowels.
- How many words are there starting with “odd” letters, which I’ll set as: Z, Q, Z, J.
- Then find the longest word in that dictionary. (Say, we’re going to make a word guessing game)
- All this must be FREE (no $). And automated in code (no manual counting)
Now we have achieved ALL our goals!