You’ve undoutedly played games like hangman or seen TV games such as Wheel of Fortune where you’re supposed to guess a word by only given the number of letters (or their placeholders, blank tiles) in a given number of tries. You may have also written similar games yourself. In this post however, I’m going to turn it around. Here, my idea is for us (a human) to pick a word and let the computer guess it! Here’s the twist though, we have to write the program to help the computer solve it. The quicker it solves the better our algorithm is.
This is not a sorting or searching algorithm where we know what to look for, here we don’t know what letters are there in the word until we pick them one by one. The idea is to make the least number of picks to solve it. So, what algorithm can we come up with? No, I’m not going to use machine learning or other heavy-weight trickery to train the computer. That’s a whole different space. Here, we have two things that the computer may know…the number of letters in the word, and a database of valid words (like a dictionary).
I’m also going to keep the minimum length of allowed words to 3 letters, and the maximum will be 15 letters. And the way I’ll solve it is using Python code, and trying different methods/algorithms and doing some analytics in Excel to compare the AI performance, as well as some trends of letters and words in the canonical words list, which is mentioned below.
An obvious method would be to program it so computer will blindly pick each letter from the alphabet until all letters are guessed. That means, for a 3-letter word that has just one repeating letter such as “zzz”, best case scenario would be 1 try. The worst-case scenario would be 26 tries assuming we start picking letters from a-to-z in alphabetical order. If we went in reverse order z-to-a, then the worst-case scenario becomes 1 try. However, that’s not a reliable algorithm in the larger picture as it’d work only for this word, and it’ll take much longer to solve common words. So, how would you approach it?
While you think about it, let me set the stage by introducing the words database. I have licensed the official competitive Scrabble words list from North American SCRABBLE Players Association (NASPA). The list is up-to-date as of 2022 and contains 191,852 total words, and 191,745 3-letter words. Upon inspection, I see the maximum length of words there is 15 letters. So, in our experiment, we’re using 3 to 15 letter words only.
Back to the algorithm, we can improve it a little further by looking at some trends from that dictionary in real-time after user enters the word, because it’ll know only the length of word to guess at that point. Then instead of randomly picking each letter of the alphabet, why not extract only words of the user-entered word’s length from the list, compute each letter’s (a-z) frequency, then sort it descending and save that in a list of memory, such that, the letter that appears the most in that length of words will be at the top of the list, then the next most frequent, then the next until the least frequently occuring letter?
Now the computer will pick from that list top-down, one-by-one and it’s chance of solving most words entered by user will be solved quicker. The flow looks like this and I’ll call this algorithm v3 or Algo V3.
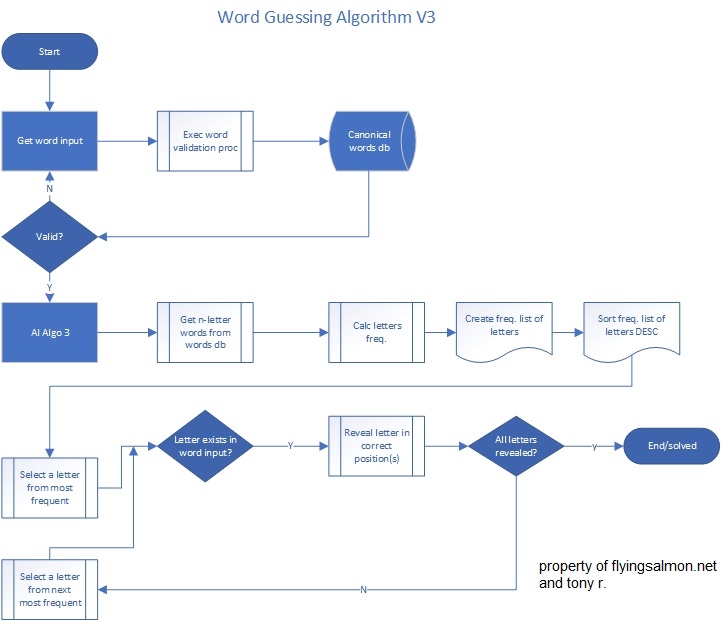
As you see in the flow, the user-entry is not a random cocktail of letters but rather must be a valid word and is validated by my program before it accepts the word and the AI starts to guess it, in addition to what’s mentioned above. Also, in the UI (we’ll look at the simple text-based UI at work soon) we display the original word with each letter hidden as a “?” or “_” (in the next version below), and if the computer’s picked letter matches, that placeholder is turned to reveal the actual letter in their appropriate position in the word. This continues until all letters are revealed, and the number of attempts the AI took is displayed in the UI at each loop (there’s a while loop along with various other for loops).
Also worth mentioning are the following. The words ‘database’ is a list of words supplied by NASPA upon licensing/membership as a text file where each word appears in its own line. There’s no other information. So, when user enters “hey” as the word, the program reads 3-letters words only the words list, then uses collections library of Python to compute frequency of every letter of every 3-letter word and then sort the frequency. There are obviously several operations involved in that (file I/O, parsing, etc.). I had already written a program that validates the user-entered word against the list and returns the result of whether it was found or not among other information. Instead of rewriting that part, I simply call that module/program from this new program and communicate across the threads and processes using config module. See my post Share Variables Across Different Modules for more information on that.
When we run Algo V3, we see output as shown below in the animation (I’ve also incorporated sound feedback during the program but that’s not shared in the animation):

As you can see for the word “zzz” (yes, it’s a valid Scrabble word), it took 24 attempts…not very good but under 26 tries. That’s because “zzz” is a very unique, unusual word with letter ‘z’, which is not a common letter in 3-letter words appearing 3 times here. So, it’s good edge case test.
However, in most other cases, it does quite well. I’ll share more performance stats below, but for now, I wanted to see if I can think of any word that’ll take it 26 tries! The word I found is “quick”. This is how it tried to guess each step and solved it after 26 tries, which is the maximum.

My next challenge is to improve this algorithm. So, I added another logic to it…instead of just going from most frequent to least frequent sequentially, what if go most-frequent, then least-frequent, then next-most frequent, then previous-least-frequent…thereby shrinking the set from two ends instead of one in each loop?
So my new algorithm, which I’ll call Algo V4 looks like this:

Let’s see how long Algo V4 takes to solve “zzz”:

Wow, it solved in 6 tries instead of 24! Huge improvement. Next, try the word “quick”…

It only took 13 tries instead of 26! Huge improvement again. These are sort of outlier words however statistically speaking. It’s clear though that for difficult-to-guess words, Algo V4 is far superior.
Next, I ran some benchmark tests using various words covering lengths of 3 letters to 15 letters…a total of 125 randomly selected words from the list and compared each algorithm’s performance. What I found is summarized below:
Mean (average) length of words: 9.7
Mean length of unique letters: 7.3
Mean attempts with Algo V3: 18.3
Mean attempts with Algo V4: 14.7
Number of times Algo V4 took more attempts than V3: 0%
Number of times Algo V4 took same attempts as V3: 45%
Number of times Algo V4 took LESS attempts than V3: 55%
Worst-case scenario (based on sample) in V3: 26 tries
Best-case scenario (based on sample) in V3: 6 tries
Worst-case scenario (based on sample) in V4: 21 tries
Best-case scenario (based on sample) in V4: 6 tries
So, the worst-case scenario is better in Algo V4 and in most cases outperforms Algo V3. There was not a single instance where Algo V4 performed worse than V3. That is some improvement indeed!
I was also curious as to the effects of length of word, and number of unique letters (non-repeating) in a word in both versions of the algorithms. So, by exporting the performance log to Excel, I calculated some correlations and did some charting to understand trends of the letters. What I found is summarized below:
Correlation between attempts and unique letters in word:
With Algo V3 number of attempts and unique number of letters in a word: 0.181
With Algo V4 number of attempts and unique number of letters in a word: 0.421 <— much stronger POSITIVE correlation between unique letters and attempts (than in Algo V3)
Correlation between attempts and LENGTH of word:
With Algo V3 number of attempts and total number of letters in a word: 0.156
With Algo V4 number of attempts and total number of letters in a word: 0.404 <— much stronger POSITIVE correlation between length of word and attempts (than in Algo V3)
We can conclude, Algo V4 is more sensitive to length of word and uniqueness of letters in a word than Algo V3.
Is it possible to improve on Algo V4 without using machine learning and training data? I’ll share some more statistics with you to help you think about that answer and possibly come up with your own algorithm.
I took each word category by length (3 letters, 4 letters…15 letters) and computed every letter’s (a to z) frequency from the official words list, then charted them in two ways to get a visual trend for them all. I’m sharing just a sample of such charts below…
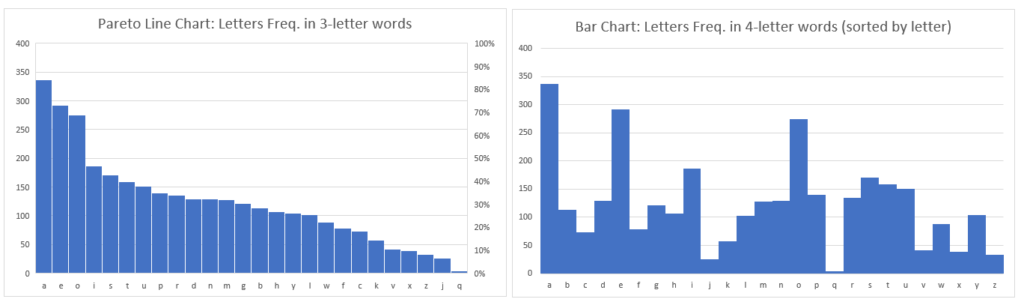
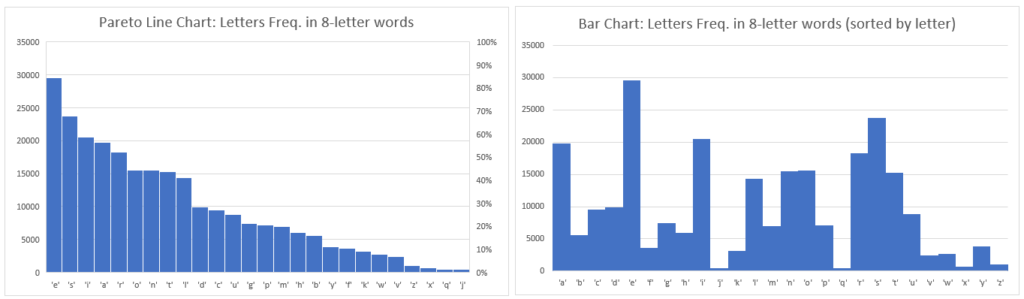
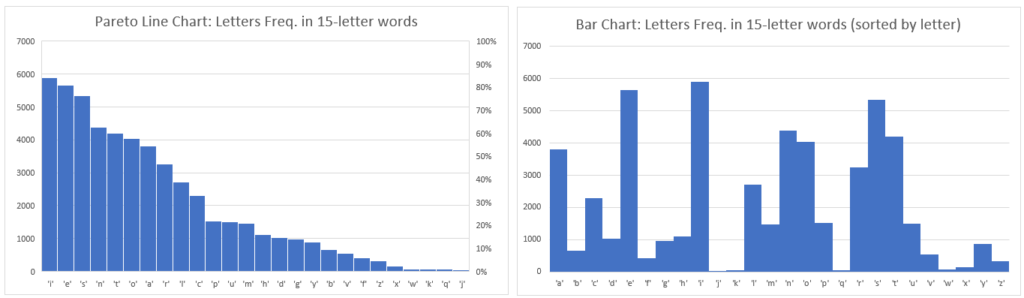
OBSERVATION: For 3 to 7-letter words, the most frequent letters are generally e,s,a (and o for 3-letter words only) and least common are q, j, and x or z. For 8-letter words, the most frequent letters are generally e,s,i (and o for 3-letter words only) and least common are j, q, and x or w or k. Letter e is most common for 9-letter words (@~33k). Probabitliy of letter e increases dramatically by word length especially in over 4-letter words until 13-letter words. Probablity of letter i is slightly higher than of e when words contain 14 letters or more. Letter s is the most common consonant. Letter n is next most common consonant if word’s length is 11 letters or more. If less than 11 letters, then letter r is after s as the most common consonant.
With this data, and perhaps you can also utilize some metrics on letter proximity in English language, you may be able to invent a better algorithm. Good luck and happy experimenting 🙂
I intentionally did not share the Python codes for Algo V3, Algo V4 implementations here as the idea is to share concepts, not to teach programming. However, if you’re interested in either or both implementations along with the UI and word validation code, feel freel contact me for the source code (it’ll not be free but very affordable just enough to recoup my time+effort. Also, I cannot share the official words lists as you have to license it yourself from NASPA directly, legally and I can point you to the right contacts to get that file.)
▛Interested in creating programmable, cool electronic gadgets? Give my newest book on Arduino a try: Hello Arduino! 
▟