Imagine we are business owners who provide a range of services. We have a large set of customer data but we really want to target those customers who might be interested in your services. We want to extract only that subset of data based on our services. And since we provide multiple, diverse services the criteria are different. In this blog, I’ll show you ways to do just that, furthermore, I’ll show you how to make this easy for any user to visually select and get results with a click: Select a service, and out comes the list of customers we should target!
I’ll start with a basic data set about target customers (their name, location, age, income, etc.), get some basic stats on them, then extract very specific items based on multiple criteria. The criteria being, if the customers fit certain income/age/gender, etc. profile, then we can target your ads on them.
For brevity, I’ll keep that within 30 records, but same method can be used for very large sets.
Our Services
Let’s assume that we provide the following services:
- Yardwork
- Roofing
- Beauty Products
- Pet Grooming
- Sports Programs
- Childcare Assistance
For each type of service, our criteria will differ. Let’s also assume the following criteria for each:
- Yardwork: Homeowners with top 5 income (all genders).
- Roofing: Homeowners with top 3 income (all genders).
- Beauty: Products Only females with top 5 income (income range within female group, not all genders)
- Pet Grooming: Pet owner, 20 years old…with >=1 cat or dog.
- Sports Programs: Who have >=1 children and at top 3 income range (all genders). Exclude seniors.
- Childcare Assistance: Who have >=1 children and under 40 with below-average income.
We will need to enforce these rules or criteria in our data extraction formulas/queries.
The Data
NOTE: All customer data is “fake” and randomly generated for this exercise. Any association with a real person is pure coincidence.
The dataset looks like this, except the columns in blue (age, senior, Rank-income, etc.) are calculated based on the basic data…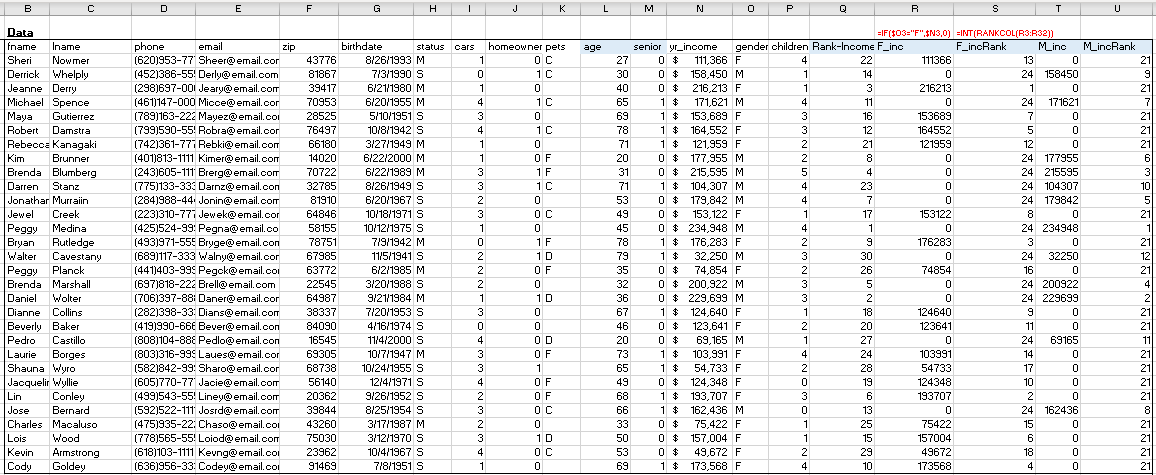
The Prep
The age is the difference between today’s date’s year portion minus the year portion in the birthdate column. Senior is a state column that’s set to 1 when someone’s age is 65 or over. Rank-Income ranks the entire list 1 to n using RANKS(). Then we extract only Incomes for female (based on gender column in given data) and then rank it separately (F-inc, and F_incRank are those columns). Then we do the same for male. We’ll need that breakdown because of the services we provide and target different demographics accordingly.
While we’re at, we should extract the basic statistics on the data on-hand (this enables us to do further, granual queries later, which will not all be discussed here). It may look like this: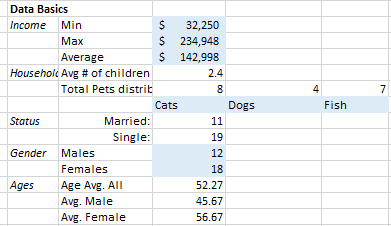
Some functions used to extract subset for the above basics are: countif(), averageif(). For example we see that there are 8 cat-owners, 4 dog-owners, 7-fish owners; we also see gender and age distributions, number of children, etc.
Since income is a major factor, we should also get top x incomes for all genders, and then by specific gender.

There are different ways of doing that but large() is a handy one for this. Then we can find the min/max…we’ll find out why this is so useful later on.
So, we have the customer list, a basic breakdown and analysis of the list, we have defined the criteria for each of our services…now it’s time to build an interactive data extraction UI!
The UI Vision
Here’s a clip of the finished UI, but let’s take a peek so we know where I’m headed:
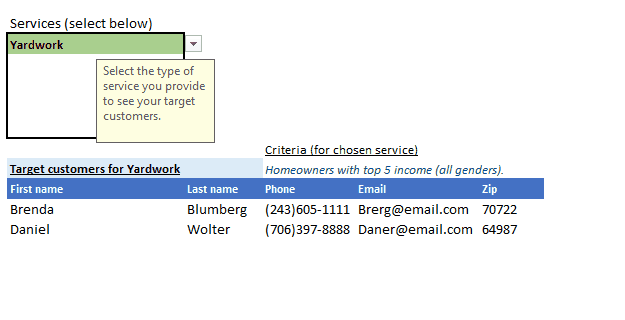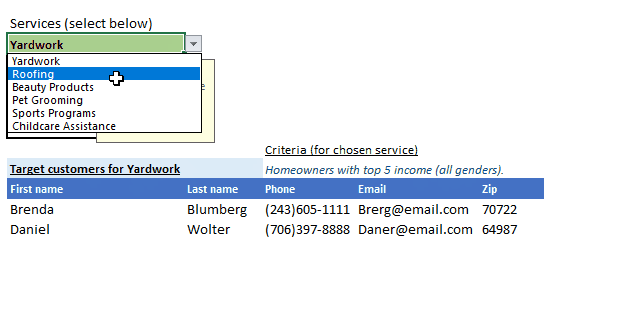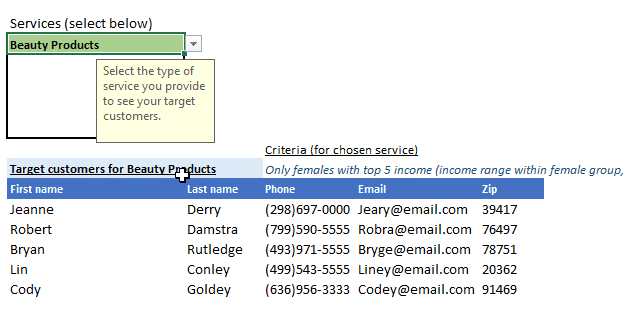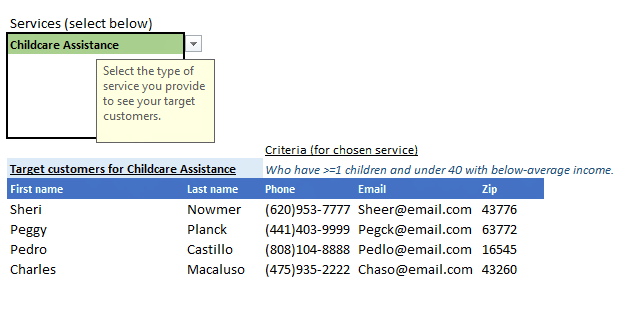
As you can see all our services are easily discoverable, with criterion for each appearing and updating as you select a service, and most importantly the results containing ONLY the customers you need to target for the selected service appears neatly in the results table. The table header also updates based on your service selection so it’s clear which target list that would be for.
The Plumbing
The dataset is in an Excel tab called “data“. The criteria list is in its own tab called “Criteria“, and the final UI (where user will be interacting with only) is in its own tab “UI“. This naming will help you to follow along the formulas.
Let’s see how this is put together. It’s not difficult, rather a series of clean steps moving decisively toward our clear goal.
First, build a drop-down list with data validation. The list items (mine is in K6:K11 of the UI tab, and then hidden to avoid distraction for a user or accidental modification) are the source for this drop-down. Each item (name of the service) contains their respective criteria text (as set earlier) in Criteria tab’s column B and D where B is the service title, D is the criteria text which is shown in the UI tab dynamically.
This is done with IFS() so when “Yardwork” is chosen from the list, the formula will match it with what’s in Criteria for output table’s headers and more critically, run the appropriate query to extract the target customer info for yardwork service candidates from the entire dataset in data tab. The customer info we want in this case are: First name, Last name, Phone, Email, Zip.
Assuming the data range is B3:U32 (about 30 records and including all the columns originally and helper columns we created earlier), and the column order and naming are the same as the data snapshot above, the complete formula that handles all our services extracting each one’s target customer list is:
The concept is exactly the same regardless of language used. e.g. SQL’s SELECT statement would achieve the same in a SQL server environment. Python has its own syntax, etc. Here, I used Excel functions…The AND and OR operations are done with “*” and “+” respectively and obviously interpreting the criteria text above into a structured query is the KEY! This means paying specific attention to words like “either”, “or”, “and”, “but” we use in everyday language and translating them to discrete instructions for the computer. The placements of parentheses can be the critical difference between getting garbage results and pinpointed results. So, it’s worth looking at the criteria text above for each service again and verifying the function and results.
Note that with the new LET() I can abstract it further and make it look simpler but it’s not publicly available at the time of this exercise. Some of the comparisons in the formula are dependent on the MIN/MAX/
Average, and Top N (income ranking) calculations we did above. So, for example to get the female customers who are in the top 5 incomes within female income category, we extract the females income group, then rank them, and then get the top N and start with the MIN of those 3 so we can simply say something like “if income is greater than or equal to this minimum income from this top N list, get the data for that person”…essentially, guaranteeing that if you state >= Min of top 3, it’ll cover all the 3 income ranges from that group! And same goes for top 5, or top 10, etc. — that’s why I calculated the MIN for each top N category. While it can be done other ways, this keeps the already long formula much cleaner and easier to understand in my view.
I hope this was helpful and interesting.
To recap, this is what it does:
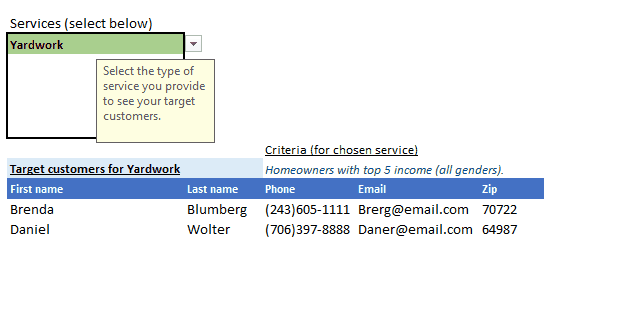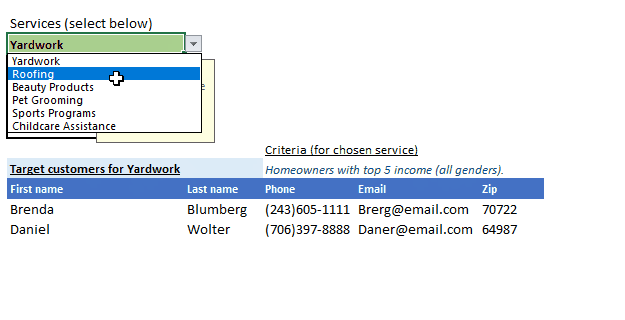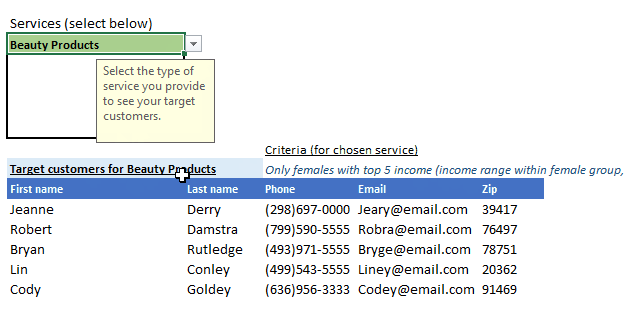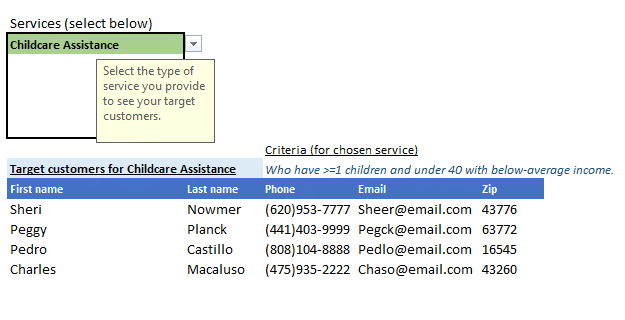
This post is not meant to be a step-by-step, detailed tutorial, instead to serve key concepts, and approache to problem-solving. At the least, to evoke curiosity. Basic->Intermediate knowledge is assumed.
If you like more info or source file to learn/use, or need more basic assistance, you may contact me at trseattle at outlook dot com. To support this voluntary effort, you can donate via the Home page.