In either case, read on.
I collected a dataset of poplular baby names from OpenData government site of City of New York ranging from 2011 through 2016…exactly 19,418 records.
Original dataset view: 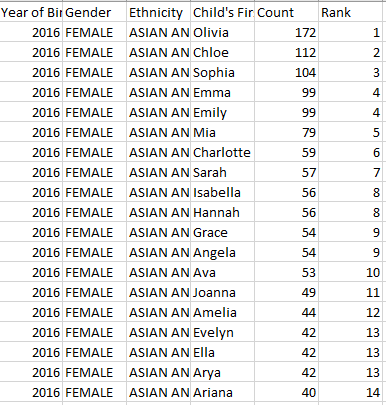
What I want to do is find out: a) Most popular names b) Less popular names (or rare names used) c) Slice it by gender d) Slice by ethnicity as recorded in the dataset e) And get results from complex queries such: show me Hispanic female baby names for year x that are in the top nth percentile.
Fields in original CSV dataset: Year of Birth, Gender, Ethnicity, Child’s First Name, Count, Rank
Ok, let’s get to work. First, the dataset (as usual) was not really clean. There were duplicates in names that I must remove since for my queries, I want unique names and their distinct counts. Secondly, the ethnicity entries were inconsistent, e.g. “ASIAN AND PACIFIC ISLANDER” and “ASIAN AND PACI”, and sometimes “HISPANIC” spelled out wholly, sometimes just as “HISP”. So, I cleaned those up using automated methods in Excel. Now that I have a cleaner table, I can now work to retrieve different results and create some visualizations for easy consumption.
The top 5% of the names (all genders, all ethnicity) are now tabulated and I added in-cell histogram that quickly shows the trend. Then each of the key fields such as name, gender, year when data was gathered (2011-2016), and their counts are easily shown as below.
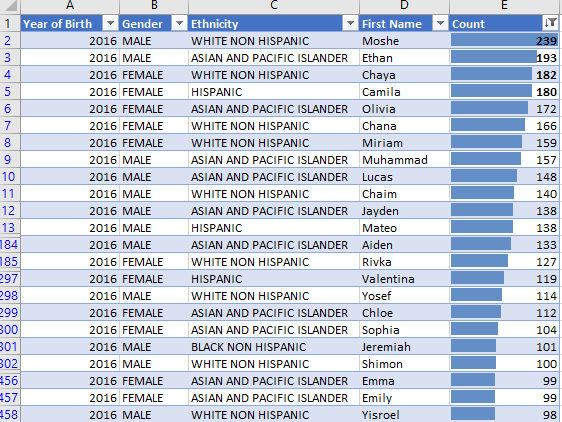
Now I have most of the filters I need, except I want a more complex way of filtering and mixing and matching parameters based on Ethnicity field. To achieve it, I add an interactive slicer. Now I can do really complex queries and see the results right-away very easily! Look at the recording of a sample interaction of we can do now with the stagnant data:
Similarly, I created another dataset that covers the least popular names from the dataset (i.e. bottom 5%). A sample snapshot of the result is shown below:
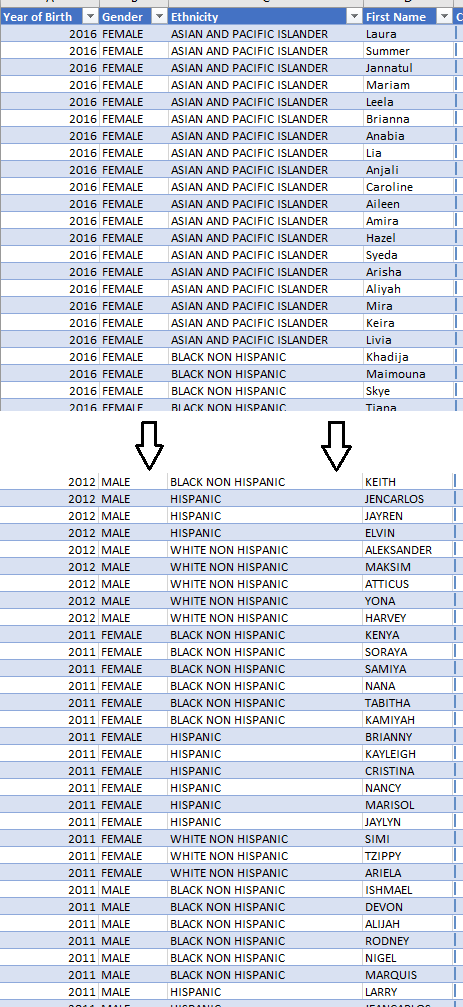
To extend it further, why not publish an interactive version online for anyone to play with? Especially for the non-geeky parents. So, I create a Word Cloud (names most common appear in larger letters, differentiated by colors and fonts) and published in online here for you to play with! The interaction animation is shown below (followed by the actual link to the service):
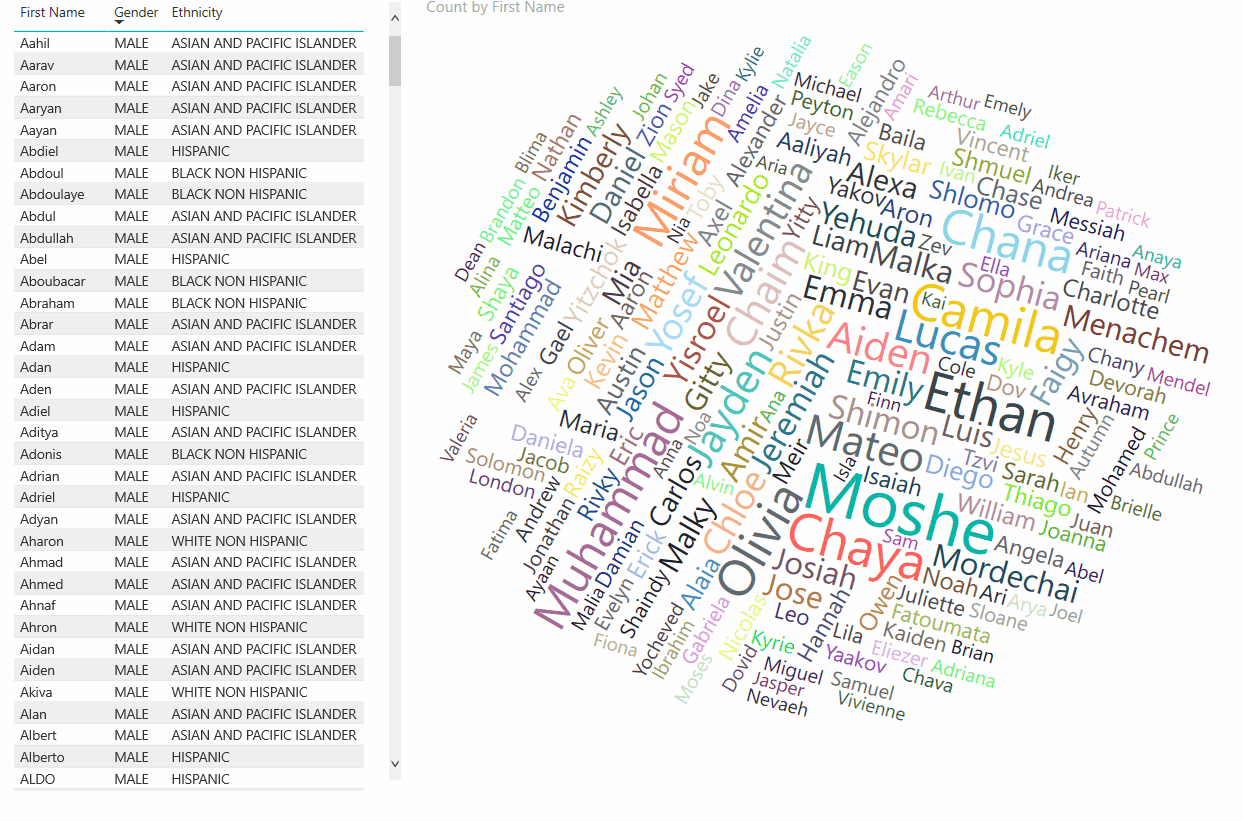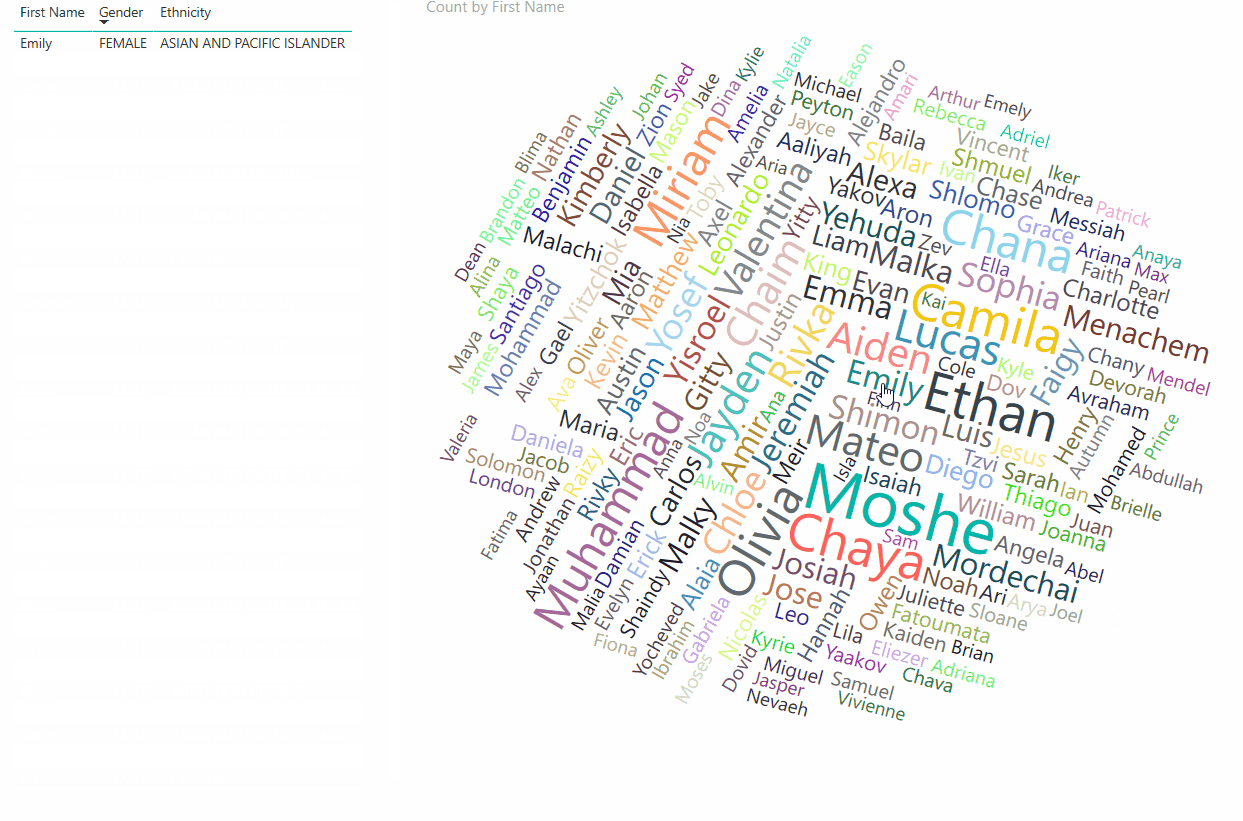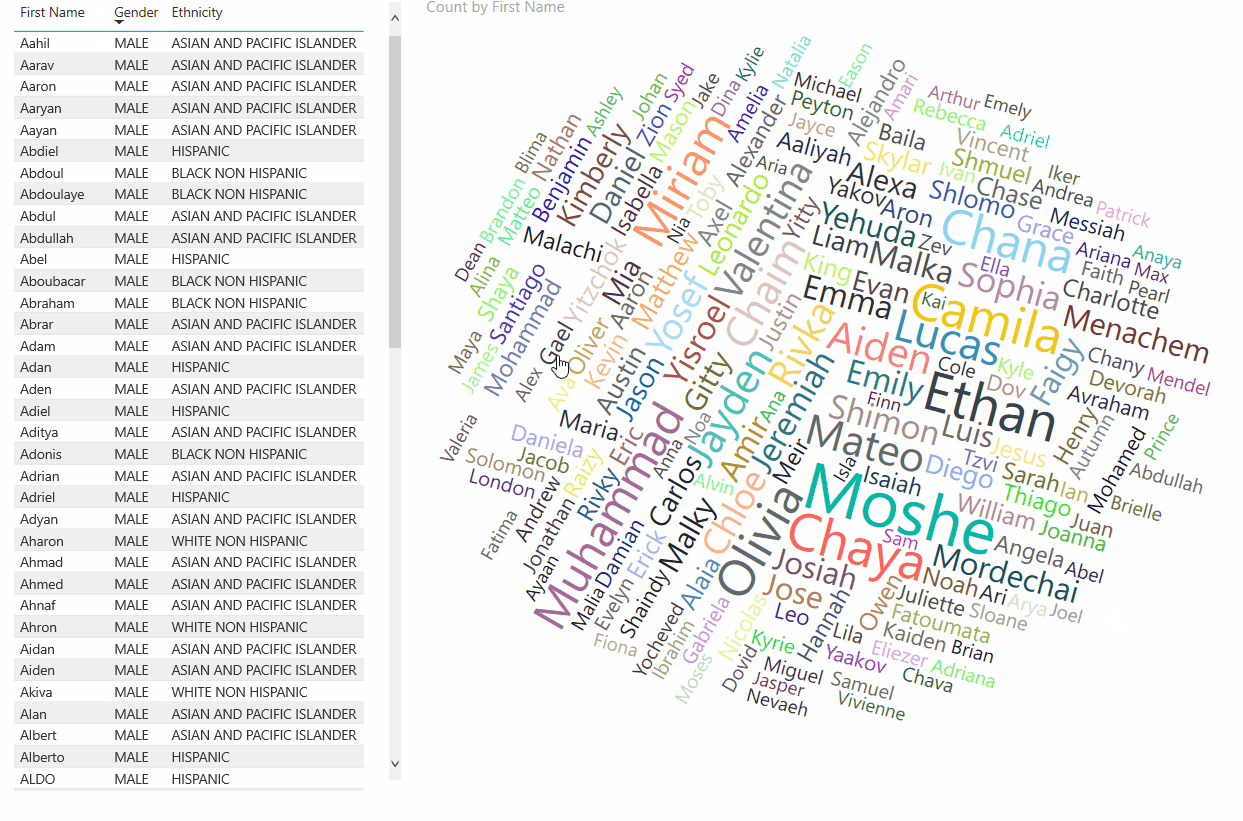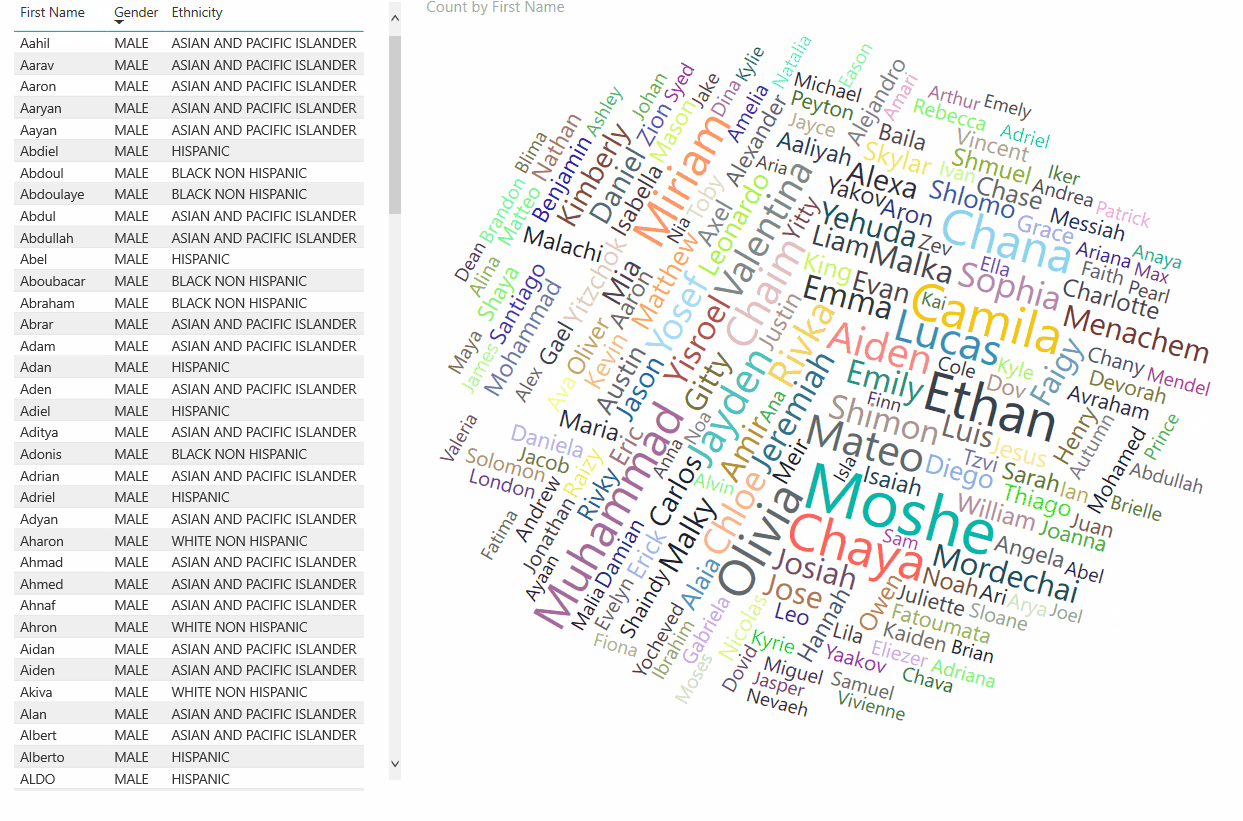
AND FINALLY, the above interactive report can be accessed from here. Hope you have fun with the data, or get ideas for naming your babies 😉
Till next time.