Today, I’ll share some information on one of the latest transformer-based TTS (text-to-speech) or text-to-audio that’s generating some buzz. Yes, AI.
While there are several really great models out there from IBM, Microsoft, Google for example, this one’s a little different. Let me introduce Bark.
By the way, to see older posts on TTS related topics by me with full code downloads click here: https://flyingsalmon.net/?s=TTS
Created by Suno (based in MA, USA) it’s described by the creators as: Bark is a transformer-based text-to-audio model created by Suno. Bark can generate highly realistic, multilingual speech as well as other audio – including music, background noise and simple sound effects. The model can also produce nonverbal communications like laughing, sighing and crying.A few things separate Bark from the rest: It’s open-source. It’s extremely natural-sounding with ability to mix multiple languages in a conversation (as humans often do: e.g. throwing in English terms in the middle of speaking Hindi, etc.), and more impressively it’ll actually say the secondary language words with an accent of the primary language speaker 🙂 That’s pretty cool and makes it sound like most human.
Another key feature of Bark TTS is its ability to generate speech in real-time. This means that users can input text on the fly and receive an immediate audio response.
It also has the capability to fully clone voices from input audio but currently restricted publicly to prevent abuse or misuse. Overall, Bark is an improving (currently undergoing crowd-testing) model that’s a versatile option for developers who need to create voice-based applications for a global audience while keeping licensing costs low (it’s open-source but not free for commerical use but is cheaper than other alternatives).
What did I do with it?
The documentation is sparse at this time, but with the given information we can play with it enough to appreciate it. There’s a custom playground in the works and they’re taking names for the waitlist, but they have a Hugging Face Playground where no development environment or coding is necessary…users can just enter a text prompt and get the generated voice. However, be warned that the queue there is looong! You’ll have to wait a good amount of time just to get one simple output. In reality, it still needs a few iterations before the output is satisfactory. There are times it generated complete, unusable garbage…more on that below with example. The upside is, it’s evolving and rapidly getting better and will definitely be widely used in many industries for many purposes.
So, instead of the Playground, I used Jupyter notebook provided by Google’s Colab and installed all required libraries and models from Google drive locally. I’m not even using GPU and not even the fastest machine I have, but it works quite fast for short paragraphs. The language used for the following examples is Python.
Code snippets & example outputs

The code and instructions to set up the Python environment is shown above. It took about 2 minutes to get that part done.
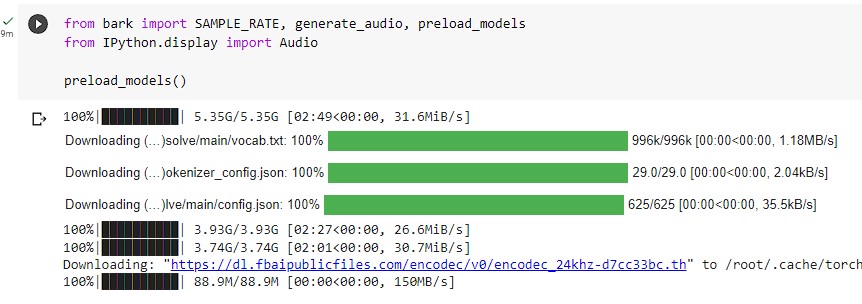
Next was to import required libraries and modules for bark as well as Python’s audio library for playback. That part took 10 minutes or less. And that’s the last thing I needed to do before actually using Bark to send it a prompt and generate some audio files.
The examples below show slightly different parameters along with their outputs. Click the play button in the audio player below each code block to hear corresponding outputs. Next to each code block I’ve included the time it took to process on my mini-desktop in seconds.
In the first example, I’m using [sigh] and [laugh] emotions along with a singing tone for text enclosed within ♪ symbols.
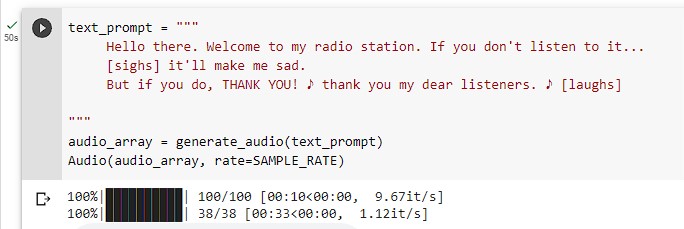
This was very realistic after a couple of tries. In the next one, I test the mixed language prompt and how it can simulate accent.
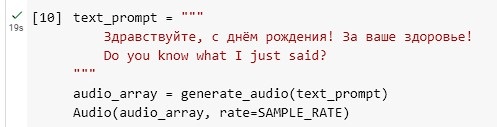
In the above code, the prompt starts with Russian (for “Hello, happy birthday. Here’s to your health.”) followed by an English sentence. It did good detecting the primary language and then speaking the 2nd sentence in his primary language’s accent.
In the next block I specify the language (Chinese-simplified) along with mixed language. It did a pretty good although the accent is not as pronounced here. Also, I noticed it sometimes adds some extra words on its own 😀 …so, not sure what the last words in Chinese it decided to insert!

In the next prompt, I added some emotions, non-verbal cues such as: “That was...well, [gasps] terrible! JUST TERRIBLE! [clears throat] Ok. Later.“
And it outputted a realistic audio as follows aside from the gasp being too long and metalic.
On the second iteration, it did better. The [clears throat] was the right audio (before it was more like a sigh) and gasp was not as artificial. Here’s how it sounds now:
Finally, the weirdest one where it was supposed to be a conversation between a man and a woman according to their API documentation, however, it completely messed up the interpretation and instead created a tune 😀 Listen to that below.
Where can I read more?
Find more info on Bark Github page here. They also have a very active Discord page here.
Hope you enjoyed this post.