We occasionally see reading time estimates in online news, blog sites, and even in promotional contents. This estimate is important because it tells the reader upfront how much the content may take to read. There are several extensive studies done internationally (in English speaking countries) that demonstrate that people tend to read messages/contents up to 2 minutes, especially in mass communication or at work. If you’re a CEO, a blog writer, a marketer, presenter, a content write of any sort, it’s important for you to understand how long you need your reader to be engaged. Is it too long? Can it be compressed and made more succinct? And then how do you estimate that? In this blog, I touch on that, and will write a full application that allows us to estimate reading time from any text file, or clipboard, whether it’s a single line or a multi-lined content.
First, the math to calculate the reading time is duck-soup. However, the challenge is that you don’t know what every reader’s ability is in terms of reading speed. Reading just to read fast is one thing, but you also need the reader to be engaged and take away some message…so you have to consider the time of reading + comprehension. You also need to consider the language in which it’s written and the reader’s command of that language. Frankly, there’s no way for you to know for sure! Your readers can be anyone online. But, we can make reasonable estimates based on data. One common measure is a scale that is as follows:
Average 125-130 wpm
Slow 90-100 wmp
Fast 150-160 wmpHowever, I also see sites that go very aggressive on these numbers, because it’s the denominator, by increasing this figure (words per minute), they can present shorter reading time to the audience, and thus hoping to at least lure them into reading the content. I’ve seen 200 or so used. I don’t personally think it’s a good, across-the-board representation of reading and comprehension. I tend to use about 155. Additionally, I don’t round up the denominator.
The manual yet easy way to estimate your reader’s time is to count the words in Microsoft Word or another editor (that shows the count of words) and then divide by the reading speed. But if you’re writing a lot of variable lengths of contents and especially if you’re in a different editor (or html editor), it’s cumbersome to check the number of words in your content every time, and then do the simple math over and over again. So, why not automate it? In this post, I’m sharing that very solution! This straight-forward Python application can read a file’s content (if you give it a file name), or read the pasted material from clipboard (single line or multi-line). I’ll share the shell-driven version of the application. Sure, you can turn it into GUI application using tkinter or other libraries as well, but I think this shell interactivity demonstrates slightly more coding creativity from developer’s perspective (and it’s not made to be a polished end-user application, rather a functional, light-weight, application to yield immediate and accurate outputs). So, let’s go over what we need to do in order to build this out.
First, we’ll get user input from the command line. The first argument supplied can be either a file name (in current directory, if no path is specified), or file name with full path (including network paths), or it can be an indicator for the app to say “I want to paste a single line that you should analyze” or “I want to paste multiple lines that you should analyze but I don’t know/care how many lines…you figure it out”. If a file name was given, I should also be able to specify how words are defined. In most cases, they’re separated by a space in-between words. But in CSV cases, they’re separated by commas, and in other cases, it may be tabs or other characters. The user should also be able to specify that delimiter so that it works on any type of content arrangement.
The code to process these are different, so the app will read the arguments and then branch off to call our custom functions accordingly and then bring all of it together to simply display the count of words (in file, or pasted, or typed content) and the estimated reading time. So, let’s look at some sample outputs of the program…
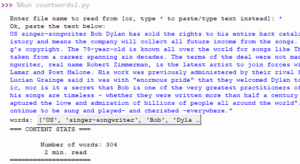
In the above case, because “*” was the input (as opposed to a file name), the code asks user to paste the content. The content was copied to the clipboard as a single line, then pasted as the input argument. For brevity, this will analyze a single-line text. Let’s look at another scenario…

In the above case, we give a file name with a path (different from the current working directory) and we also get to define the delimiter in the file. If user just hits Enter without specifying a delimiter, typical space delimiter will be used, otherwise, it’ll use that specified character to yield the accurate result. All the content is inside the file (with line breaks, punctuations, symbols, etc.) And finally, one more scenario…

Here, we pass “?” argument indicating to the app that we want multi-line inputs (either pasted or typed)…therefore, the application will not just read one line (as normally done with input() function in most programming languges) but will unlimited number of line-breaks and will only finish reading the input when user indicates the “end of reading” with ctrl-D for example. We’ll look at the code details soon. In this case, the content with line breaks was copied to the clipboard and pasted as an input for the app.
LOOKING UNDER THE HOOD
Let’s take a look at the code in more detail. First, we get the user input by calling our custom function getUserInput() which returns the first argument, using which we decide which other custom functions to call: getCountFromPaste() if it’s a single-line (e.g. “*”), or getCountFromPasteMultiLine() if it’s a multi-line content, or getCountFromFile() if it’s a file name/path. Each of these functions processes the content differently but all return the count of words calculated. Finally, we call another custom function getRTEstimate() passing it the count returned by above function(s), and the desired reading speed. This separate of duties in the functions allows us to keep the code clean while extending each function further without affecting the core. The reading speed is adjustable to any value simply by passing a different value to the estimating function for example….which then returns the estimated reading time in minutes.

Next let’s write the codes for each of our custom functions. The first one is the simplest one which just uses input() and returns the value entered by user. getCountFromPaste() takes a single-line of input and breaks them into separate words (using space as delimiter, and it could take any delimiter as specified in split() by the way) and stores them into an array of words (aka a list in Python).
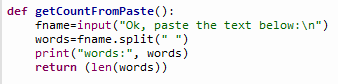
getCountFromPasteMultiLine() is a lot trickier. Because input() works only line at a time, the app would finish inputting as soon as a line-break would be encountered—but in this case, we need to continue to process as many lines as user pastes or types! To achieve that, we have to put the input() in a forever loop until a signal is entered by user to indicate “I’m done entering”. That signal is EOFError which can be generated by ctrl-d on keyboard. In the loop we have to continue to read each line, load it up into an array to keep track of lines, and another array which will split each line into each word contained in the line. And also keep a counter that will continuously update the count of words inside the loop.

The getCountFromFile() looks something like this:
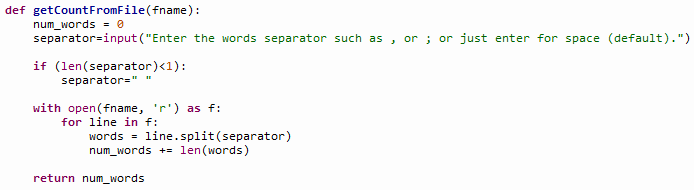
— which is straight-forward, but notice the processing of the delimiter (var name: separator in the function). Back in the main body of the code, all we have to do then is print on screen the returned values (words, reading time) in whatever fancy format we like. Because we want the reading time to be in minutes and not in fractions or show zero for short content, we can fine- tune the message to a more sensible one by this snippet:

which will show “Less than a min. read” for those that are less than a minute read and will show “3 min. read” for those that are 3 minutes and so on just by converting the reading time into a string and concatenate the conditional label to it.
Hope this was a fun read. With this fun little app, I never have to count the words using another application and estimate the reading time manually ever again 🙂
▛Interested in creating programmable, cool electronic gadgets? Give my newest book on Arduino a try: Hello Arduino! 
▟